





发布时间:2021-01-12 10:42 作者:未知
简述:今天腾佑AI人工智能给大家带来百度提出统一模态学习方法UNIMO的相关信息,下面我们来看具体详情:
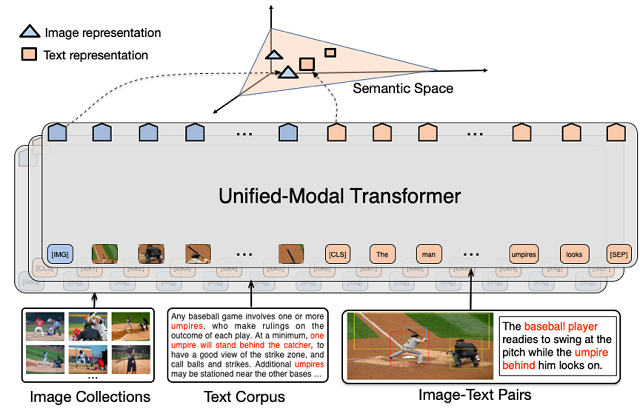
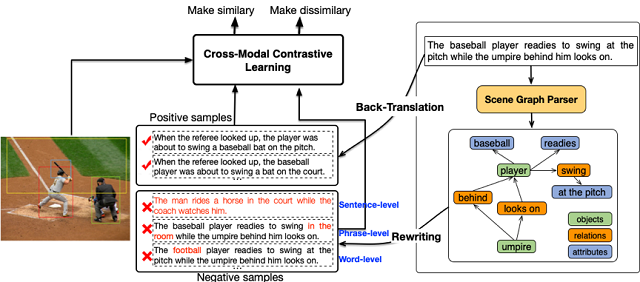
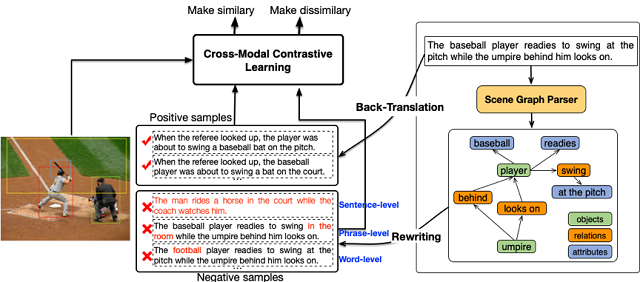
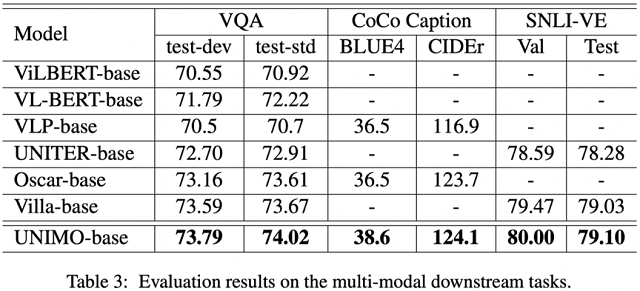

腾佑AI(ai.tuidc.com) 成立于2007年,一直致力于发展互联网IDC数据中心业务、云计算业务、 CDN业务、互联网安全及企业客户技术解决方案等产品服务, 2018年成为百度云河南服务中心。主营服务器租用,服务器托管,虚拟主机, 域名注册,机柜租用,主机租用,主机托管,带宽租用,云主机,CDN加速 , WAF防火墙,网络安全,人脸识别,文字识别,图像识别,语音识别等业务;
售前咨询热线:400-996-8756
备案提交:0371-89913068
售后客服:0371-89913000

热门活动

热搜词
热门产品推荐

















联系方式
400-996-8756
微信公众号
手机站
COPYRIGHT 2007-2020 TUIDC ALL RIGHTS RESERVED 腾佑科技-百度AI人工智能_百度人脸识别_图像识别_语音识别提供商
地址:河南省郑州市姚砦路133号金成时代广场6号楼13层 I CP备案号:豫B2-20110005-1 公安备案号: 41010502003271
声明:本站发布的内容版权归郑州腾佑科技有限公司所有,本站部分素材来源于网络及网友投稿,若无意中侵犯了您的版权,请致电在线客服我们将在核实后予以删除!




