





发布时间:2022-01-11 09:45 作者:创始人
简述:今天给大家分享的是百度AI中英文OCR结构化模型StrucTexT预训练模型揭秘,下面我们一起来看具体详情!
今天给大家分享的是百度AI中英文OCR结构化模型StrucTexT预训练模型揭秘,下面我们一起来看具体详情!
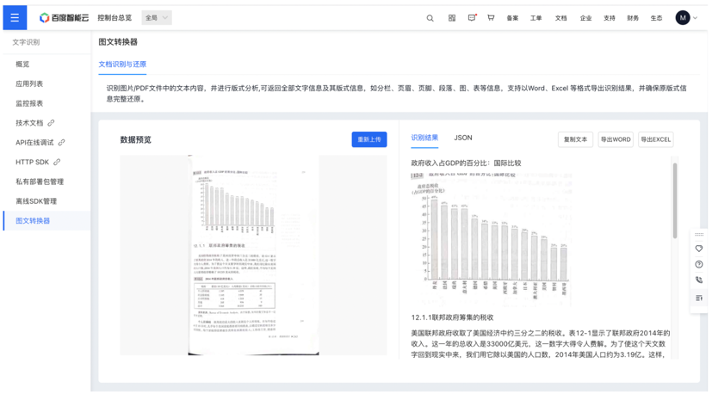
光学字符识别(OCR)是目前应用较为广泛的视觉AI技术之一。随着OCR技术在产业应用的快速发展,现实场景对OCR提出新的需求:从感知走向认知——OCR不但需要认识文字,也要进一步理解文字。因此,结构化逐渐成为OCR产业应用的核心技术之一,旨在快速且准确地分析卡证、票据、档案图像等富视觉数据中的结构化文字信息,并对关键数据进行提取。OCR结构化技术通常要解决两个高频应用任务类型:
实体分类:提取OCR结果中与预定义实体标签(例如“姓名”,“日期”等)对应的文本内容;
实体连接:分析文本实体间的关系,例如是否组成键(key)-值(value)对、是否属于表格里的同行或同列。

OCR结构化技术的应用需求广泛存在。在企业活动中,处理报表、合同、表单和发票等文件资料已经成为日常办公的重要工作。OCR结构化技术能够帮助企业自动化理解和识别文档、票据中的关键信息,降低人力成本,提升运营效率。

百度提出OCR结构化模型StrucTexT,首次将中英文字段级多模态特征融入OCR结构化预训练进行特征增强,在6项OCR结构化数据集合上努力刷新了业界内较好效果;同时基于StrucTexT打造数字化医疗理赔方案,助力企业无纸化办公、数字化转型。
业界首个中英文字段级多模态特征增强OCR结构化模型StrucTexT
现有的OCR结构化方案可以分为文本信息提取方法,图像信息提取方法和多模态信息提取方法:
文本信息提取方法:基于自然语言处理,提取图像中的文字序列,利用命名实体识别技术标记文本语义实体;
图像信息提取方法:基于检测分割等计算机视觉任务,定位文本实体的图像区域;
多模态信息提取方法:档案、票据、卡证等富视觉文本图像具有文字、图像(纹理,颜色、字体等)、布局(空间位置)的多重属性。这类方法综合采用多模态线索进行建模,表现出更优的效果。

近两年,多模态预训练技术的加持给OCR结构化模型性能和泛化性带来了显著收益。然而,现有的预训练模型主要在字符(中文上为单字,英文上为单词)粒度进行建模,忽略了文本在图像上的视觉文字行结构特性,难以对文档语义和视觉信息进行高效表示。
为了解决这一问题,百度OCR提出联合字符级别和字段级别的多模态预训练模型——StrucTexT:
1.首创字段级多模态特征增强:提出字段级文档结构建模,结合文本序列,提出遮罩式视觉语言模型、字段长度预测、字段方位预测,更有效理解富视觉文档。
2.中英文场景上效果全面领先:覆盖4w+中英文常见字词,实现业界较大规模5千万OCR中英文场景数据预训练,深度挖掘不同模态间的语义关联。
3.完备的OCR字段解析能力:基于双粒度输出框架,灵活的建模粒度选择,可支持字符信息抽取、字段信息抽取和字段连接预测三种结构化信息提取任务。
4.单模型支持多个下游任务:支持中英混合场景的OCR场景,单模型可并行处理多个下游任务。
StrucTexT是一个基于双粒度表示的多模态信息提取模型。除了采用字符粒度建模文本之外,StrucTexT利用字段组织文档视觉线索,并构建字符和字段的匹配关系对齐图像与文本特征。在多模态信息表示上,StrucTexT构建文本、图像和布局的多模态特征,并提出“遮罩式视觉语言模型”,“字段长度预测”和“字段方位预测”三种自监督预训练任务促进跨模态特征交互,帮助模型学习模态间的信息关联,增强对文档的综合理解能力。另外,StrucTexT支持中英双语编码。在双粒度表征下,模型能够实现字符和字段粒度的信息抽取任务,实现灵活选型和场景适配。

多粒度建模+多模态特征=StrucTexT效果全面领先
基于多粒度建模和多模态特征增强,StrucTexT在OCR结构化的3种任务场景、4个数据集的6项榜单上均取得了业界领先的效果。
1.字符信息抽取任务:StrucTexT基于预训练模型使用字符粒度的分类方式,在中文试卷数据集EPHOIE上取得了99.30%的卓越效果。

2.字段实体分类:StrucTexT使用字段特征进行实体分类,在票据信息抽取集合SROIE,英文表单数据集合FUNSD和中文表单数据集合XFUND-CHN三个数据集上达到SOTA。值得一提的是,后两者任务上采用的是同一个finetuned模型,实现中英文应用场景的统一。
其中,StrucTexT在SROIE上预测结果字段F1值为98.70%,位列榜单第一名。

在FUNSD和XFUND数据集上,StrucTexT对预定义的四类实体类别进行分类,large模型在两个数据集上的F1值分别达到87.56%和92.29%。

3.实体关系预测:即判断语义实体之间是否存在连接关系,StrucTexT在FUNSD和XFUN数据集上以8%以上的大幅度领先优势,刷新了SOTA指标。

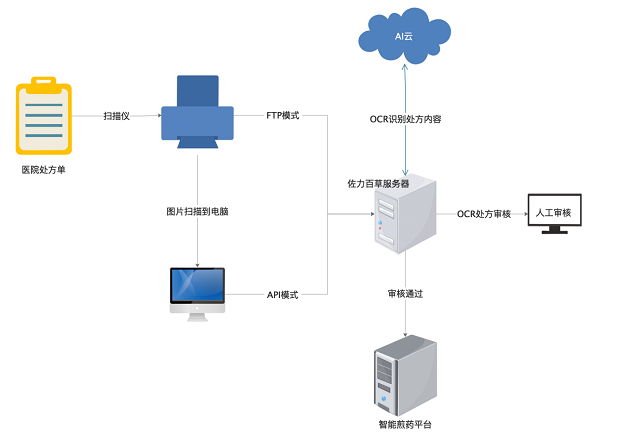
StrucTexT强力支持,医疗理赔场景复杂票据识别也通通拿下
医疗保险理赔是OCR结构化信息提取的重要应用场景。中国商业健康保险近十年的年复合增长率超过28%,2020年健康险保费收入超8000亿。银保监会提出力争到2025年,商业健康保险市场规模超2万亿元。随着健康险业务的快速发展,保险公司要处理的理赔案件日益增长。
传统保险公司通过人力进行核保,理赔人员手动录入票面上的内容信息,少则十几条,多则数十条。理赔录入审核团队规模逐年递增。大量成本的投入给公司运营带来了巨大压力。为了提升业务效率,降低运营成本,利用人工智能技术实现智能化理赔成为保险公司改善理赔流程的好助力。
实现自动化理赔,准确识别医疗影像的信息是关键。然而,医疗影像识别场景较为复杂,准确的OCR结构化提取信息是一个长期困扰业界的难题:
1.票据种类繁多:单单常见的清单、发票、检验报告单就有上百余种。
2.票据版式不一:各个省市医院输出版面各有不同,形式纷繁复杂。医疗机构为了方便,往往不按照规范打印,内容排版极为随意,存在遮挡、偏移、叠字等较强干扰。
3.图像采集不规范:健康险属于C端服务,用户拍照行为不规范,单据存在折损、弯曲、形变等问题,上传的图像质量不高。
4.票据排版复杂:医疗单据属于多类型文字混排,包含中英文、数字和特殊符号,文字识别难度大。




针对上述问题,百度基于业界领先的OCR识别能力以及StrucTexT OCR结构化技术能力,与大型保险公司进行合作,构建数字化医疗理赔方案。得益于StrucTexT模型对泛版式的多种复杂医疗影像的OCR结构化能力,通过结合行业业务术语,研发医疗影像结构化信息提取能力,在上层进行专业术语标准化输出,实现核保系统智能化。目前,搭载了医疗影像OCR结构化能力的医疗理赔方案,已经在多家客户的实际理赔核保业务中得以应用,其中某保险行业头部客户采集能效提升了4倍。
医疗发票OCR结构化:

检查诊断报告OCR结构化:

费用结算单OCR结构化:

医学检验报告OCR结构化:

出院小结OCR结构化:

2020年9月22日,中国在第七十五届联合国大会上提出:“中国将提高国家自主贡献力度,采取更加有力的政策和措施,二氧化碳排放力争于2030年前达到峰值,努力争取2060年前实现碳中和”。OCR结构化是实现信息电子化、办公智能化的基础核心技术。在日常工作中存在海量的卡证、票据和富文档图片数据,需要进行OCR识别和结构化录入。基于中英文字段级多模态特征增强的OCR结构化模型StrucTexT,可以对社会各行各业的办公流程输入、各类文档证件进行数字化录入,为促进无纸化办公、企业数字化转型、实现国家“双碳”目标奠定了良好的基础。
目前StrucTexT模型已经在飞桨PaddlePaddle上开放,了解更多StrucTexT技术细节,可以通过以下链接:
StrucTexT论文地址:
https://arxiv.org/abs/2108.02923
StrucTexT开放模型:
https://github.com/PaddlePaddle/VIMER/tree/main/StrucTexT
更多百度AI文字识别相关内容,百度云服务中心持续分享中!
推荐阅读:百度大脑OCR技术助力审批管理智能化
腾佑AI(ai.tuidc.com) 成立于2007年,一直致力于发展互联网IDC数据中心业务、云计算业务、 CDN业务、互联网安全及企业客户技术解决方案等产品服务, 2018年成为百度云河南服务中心。主营服务器租用,服务器托管,虚拟主机, 域名注册,机柜租用,主机租用,主机托管,带宽租用,云主机,CDN加速 , WAF防火墙,网络安全,人脸识别,文字识别,图像识别,语音识别等业务;
售前咨询热线:400-996-8756
备案提交:0371-89913068
售后客服:0371-89913000

热门活动

热搜词













联系方式
400-996-8756
微信公众号
手机站
COPYRIGHT 2007-2020 TUIDC ALL RIGHTS RESERVED 腾佑科技-百度AI人工智能_百度人脸识别_图像识别_语音识别提供商
地址:河南省郑州市姚砦路133号金成时代广场6号楼13层 I CP备案号:豫B2-20110005-1 公安备案号: 41010502003271
声明:本站发布的内容版权归郑州腾佑科技有限公司所有,本站部分素材来源于网络及网友投稿,若无意中侵犯了您的版权,请致电在线客服我们将在核实后予以删除!




