





发布时间:2022-01-14 09:25 作者:创始人
简述:今天给大家分享的是以领域预训练和对比学习SimCSE为基础的语义检索,语义检索相比传统基于字面关键词的检索有诸多优势,广泛应用于问答、搜索系统中。下面我们来看具体详情!
今天给大家分享的是以领域预训练和对比学习SimCSE为基础的语义检索,语义检索相比传统基于字面关键词的检索有诸多优势,广泛应用于问答、搜索系统中。下面我们来看具体详情!
所谓语义检索(也称基于向量的检索),是指检索系统不再拘泥于用户Query字面本身(例如BM25检索),而是能精准捕捉到用户Query背后的真正意图并以此来搜索,从而向用户返回更准确的结果。
其可视化demo如下,一方面可以获取文本的向量表示;另一方面可以做文本检索,即得到输入Query的top-K相关文档!

语义检索,底层技术是语义匹配,是NLP基础常见的任务之一。从广度上看,语义匹配可以应用到QA、搜索、推荐、广告等各大方向;从技术深度上看,语义匹配需要融合各种SOTA模型、双塔和交互两种常用框架的魔改、以及样本处理的艺术和各种工程tricks。
比较有趣的是,在查相关资料的时候,发现百度飞桨PaddleNLP近期刚开源了类似的功能,可谓国货之光!之前使用过PaddleNLP,基本覆盖了NLP的各种应用和SOTA模型,调用起来也非常方便,强烈推荐大家试试!
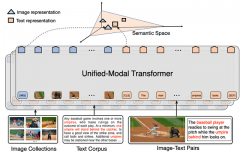
接下来基于PaddleNLP提供的轮子一步步搭建语义检索系统。整体框架如下,由于计算量与资源的限制,一般工业界的搜索系统都会设计成多阶段级联结构,主要有召回、排序(粗排、精排、重排)等模块,各司其职。
step-1:利用预训练模型离线构建候选语料库;
step-2:召回模块,对于在线查询Query,利用Milvus快速检索得到top1000候选集;
step-3:排序模块,对于召回的top1000,再做更精细化的排序,得到top100结果返回给用户。

语义检索技术框架图
整体概览
1.1数据
数据来源于某文献检索系统,分为有监督(少量)和无监督(大量)两种。
1.2代码
首先clone代码:

运行环境是:
python3
paddlepaddle==2.2.1
paddlenlp==2.2.1
还有一些依赖包可以参考requirements.txt。
离线建库
从上面的语义检索技术框架图中可以看出,首先我们需要一个语义模型对输入的Query/Doc文本提取向量,这里选用基于对比学习的SimCSE,核心思想是使语义相近的句子在向量空间中临近,语义不同的互相远离。
那么,如何训练才能充分利用好模型,达到更高的精度呢?对于预训练模型,一般常用的训练范式已经从『通用预训练->领域微调』的两阶段范式变成了『通用预训练->领域预训练->领域微调』三阶段范式。
具体地,在这里我们的模型训练分为几步(代码和相应数据在下一节介绍):
1.在无监督的领域数据集上对通用ERNIE 1.0进一步领域预训练,得到领域ERNIE;
2.以领域ERNIE为热启,在无监督的文献数据集上对SimCSE做预训练;
3.在有监督的文献数据集上结合In-Batch Negatives策略微调步骤2模型,得到的模型,用于抽取文本向量表示,即我们所需的语义模型,用于建库和召回。
由于召回模块需要从千万量级数据中快速召回候选集合,通用的做法是借助向量搜索引擎实现高效ANN,从而实现候选集召回。这里采用Milvus开源工具,关于Milvus的搭建教程可以参考官方教程
https://milvus.io/cn/docs/v1.1.1/
Milvus是一款国产高性能检索库,和Facebook开源的Faiss功能类似。
离线建库的代码位于PaddleNLP/applications/neural_search/recall/milvus

2.1抽取向量
依照Milvus教程搭建完向量引擎后,就可以利用预训练语义模型提取文本向量了。运行feature_extract.py即可,注意修改需要建库的数据源路径。
运行结束会生成1000万条的文本数据,保存为corpus_embedding.npy。
2.2插入向量
接下来,修改config.py中的Milvus ip等配置,将上一步生成的向量导入到Milvus库中。

抽取和插入向量两步,如果机器资源不是很"富裕"的话,可能会花费很长时间。这里建议可以先用一小部分数据进行功能测试,快速感知,等真实部署的阶段再进行全库的操作。
插入完成后,我们就可以通过Milvus提供的可视化工具[1]查看向量数据,分别是文档对应的ID和向量。

文档召回
召回阶段的目的是从海量的资源库中,快速地检索出符合Query要求的相关文档Doc。出于计算量和对线上延迟的要求,一般的召回模型都会设计成双塔形式,Doc塔离线建库,Query塔实时处理线上请求。
召回模型采用Domain-adaptive Pretraining+SimCSE+In-batch Negatives方案。
另外,如果只是想快速测试或部署,PaddleNLP也贴心地开源了训练好的模型文件,下载即可用,这里直接贴出模型链接:
领域预训练ERNIE:
https://bj.bcebos.com/v1/paddlenlp/models/ernie_pretrain.zip
无监督SimCSE:
https://bj.bcebos.com/v1/paddlenlp/models/simcse_model.zip
有监督In-batch Negatives:
https://bj.bcebos.com/v1/paddlenlp/models/inbatch_model.zip
3.1领域预训练
Domain-adaptive Pretraining的优势在之前文章已有具体介绍,不再赘述。直接给代码,具体功能都标注在后面。

3.2 SimCSE无监督预训练
双塔模型,采用ERNIE 1.0热启,引入SimCSE策略。训练数据示例如下代码结构如下,各个文件的功能都有备注在后面,清晰明了。

对于训练、评估和预测分别运行scripts目录下对应的脚本即可。训练得到模型,我们一方面可以用于提取文本的语义向量表示,另一方面也可以用于计算文本对的语义相似度,只需要调整下数据输入格式即可。
3.3有监督微调
对上一步的模型进行有监督数据微调,训练数据示例如下,每行由一对语义相似的文本对组成,tab分割,负样本来源于引入In-batch Negatives采样策略。

关于In-batch Negatives的细节,可以参考文章:
大规模搜索+预训练,百度是如何落地的?
https://mp.weixin.qq.com/s/MyVK6iKTiI-VpP1LKf4LIA
整体代码结构如下:

训练、评估、预测的步骤和上一步无监督的类似,聪明的你肯定一看就懂了!
3.4语义模型效果
前面说了那么多,来看看几个模型的效果到底怎么样?对于匹配或者检索模型,常用的评价指标是Recall K,即前TOP-K个结果检索出的正确结果数与全库中所有正确结果数的比值。

对比可以发现,首先利用ERNIE 1.0做Domain-adaptive Pretraining,然后把训练好的模型加载到SimCSE上进行无监督训练,然后利用In-batch Negatives在有监督数据上进行训练能获得优良的性能。
3.5向量召回
终于到了召回,回顾一下,在这之前我们已经训练好了语义模型、搭建完了召回库,接下来只需要去库中检索即可。代码位于
PaddleNLP/applications/neural_search/recall/milvus/inference.py

以输入国有企业引入非国有资本对创新绩效的影响——基于制造业国有上市公司的经验证据为例,检索返回效果如下

返回结果的较后一列为相似度,Milvus默认使用的是欧式距离,如果想换成余弦相似度,可以在Milvus的配置文件中修改。
文档排序
不同于召回,排序阶段由于面向的打分集合相对小很多,一般只有几千级别,所以可以使用更复杂的模型,这里采用ERNIE-Gram预训练模型,loss选用margin_ranking_loss。
训练数据示例如下,三列,分别为(query,title,neg_title),tab分割。对于真实搜索场景,训练数据通常来源业务线上的点击日志,构造出正样本和强负样本。

代码结构如下

训练运行sh scripts/train_pairwise.sh即可。
同样,PaddleNLP也开源了排序模型:
https://bj.bcebos.com/v1/paddlenlp/models/ernie_gram_sort.zip
对于预测,准备数据为每行一个文本对,然后预测返回文本对的语义相似度。
是文化差异。','pred_prob':0.85112214}
{'query':'中西方语言与文化的差异','title':'跨文化视角下中国文化对外传播路径琐谈跨文化,中国文化,传播,翻译','pred_prob':0.78629625}
{'query':'中西方语言与文化的差异','title':'从中西方民族文化心理的差异看英汉翻译语言,文化,民族文化心理,思维方式,翻译','pred_prob':0.91767526}
{'query':'中西方语言与文化的差异','title':'中英文化差异对翻译的影响中英文化,差异,翻译的影响','pred_prob':0.8601749}
{'query':'中西方语言与文化的差异','title':'浅谈文化与语言习得文化,语言,文化与语言的关系,文化与语言习得意识,跨文化交际','pred_prob':0.8944413}
总结
本文基于PaddleNLP提供的Neural Search功能自己快速搭建了一套语义检索系统。相对于自己从零开始,PaddleNLP非常好地提供了一套轮子。如果直接下载PaddleNLP开源训练好的模型文件,对于语义相似度任务,调用现成的脚本几分钟即可搞定!对于语义检索任务,需要将全量数据导入Milvus构建索引,除训练和建库时间外,整个流程预计30-50分钟即可完成。
在训练的间隙还研究了下,发现GitHub上的文档也很清晰详细啊,对于小白入门同学,做到了一键运行,不至于被繁杂的流程步骤困住而逐渐失去兴趣;模型全部开源,拿来即用;对于想要深入研究的同学,PaddleNLP也开源了数据和代码,可以进一步学习,赞!照着跑下来,发现PaddleNLP太香了!赶紧Star收藏一下,持续跟进新能力吧,也表示对开源社区的一点支持~
https://github.com/PaddlePaddle/PaddleNLP
另外我们还可以基于这些功能进行自己额外的开发,譬如开篇的动图,搭建一个更直观的语义向量生成和检索服务。Have Fun!
在跑代码过程中也遇到一些问题,非常感谢飞桨同学的耐心解答。并且得知针对这个项目还有一节视频课程已经公开,点击链接即可观看课程:
https://aistudio.baidu.com/aistudio/course/introduce/24902
附上本次实践项目的代码:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/neural_search
更多语义检索相关内容,百度云服务中心持续分享中!
腾佑AI(ai.tuidc.com) 成立于2007年,一直致力于发展互联网IDC数据中心业务、云计算业务、 CDN业务、互联网安全及企业客户技术解决方案等产品服务, 2018年成为百度云河南服务中心。主营服务器租用,服务器托管,虚拟主机, 域名注册,机柜租用,主机租用,主机托管,带宽租用,云主机,CDN加速 , WAF防火墙,网络安全,人脸识别,文字识别,图像识别,语音识别等业务;
售前咨询热线:400-996-8756
备案提交:0371-89913068
售后客服:0371-89913000

热门活动

热搜词















联系方式
400-996-8756
微信公众号
手机站
COPYRIGHT 2007-2020 TUIDC ALL RIGHTS RESERVED 腾佑科技-百度AI人工智能_百度人脸识别_图像识别_语音识别提供商
地址:河南省郑州市姚砦路133号金成时代广场6号楼13层 I CP备案号:豫B2-20110005-1 公安备案号: 41010502003271
声明:本站发布的内容版权归郑州腾佑科技有限公司所有,本站部分素材来源于网络及网友投稿,若无意中侵犯了您的版权,请致电在线客服我们将在核实后予以删除!




