


完善高效的形象定制流程,仅需提供300秒视频数据或一张原画设计,即可在一周内完成个性化形象的模型制作,根据需求可对服饰、姿态、表情等进行定制
支持十余种预置肢体动作,情绪、唇形根据输入的文本/语音信息自适应
基于GPU集群和快速渲染技术,视频生产效率可达1:2,快速批量生产虚拟主播视频
预置超写实拟真人、3D卡通半拟真人、3D卡通动漫三类形象库,供客户灵活选择,同时支持专属定制,打造个性化的主播形象
通过文字、语音驱动虚拟主播的唇形、表情、肢体动作,配合表情和动作个性化定制,让虚拟主播具有更加逼真的表现力
根据场景需要更改背景、添加画中画视频,实现从播报文本/音频到虚拟主播播报视频的一键式生成,支持Web编辑系统及标准化接口两种模式
可提供端上sdk版本,支持语音、文本交互,轻松实现智能对话及互动问答功能
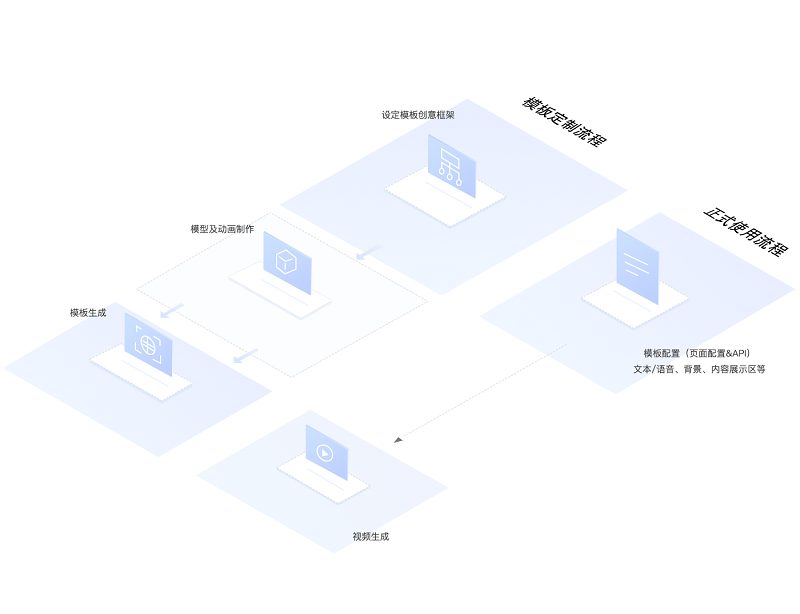
实现有趣、个性化的虚拟主播播报视频的快速规模化生产,节省媒体运营成本,可用于天气播报、趣味新闻播报等
基于百度人脸识别技术和丰富全面的公众人物库,识别视频中出现的明星、名人
基于长语音识别技术,针对视频场景优化,精准识别视频中的语音内容
联系方式
400-996-8756
微信公众号
手机站
COPYRIGHT 2007-2020 TUIDC ALL RIGHTS RESERVED 腾佑科技-百度AI人工智能_百度人脸识别_图像识别_语音识别提供商
地址:河南省郑州市姚砦路133号金成时代广场6号楼13层 I CP备案号:豫B2-20110005-1 公安备案号: 41010502003271
声明:本站发布的内容版权归郑州腾佑科技有限公司所有,本站部分素材来源于网络及网友投稿,若无意中侵犯了您的版权,请致电在线客服我们将在核实后予以删除!




