今天给大家分享的是ICML 2021顶会来袭,百度飞桨AI硬实力集中展现的相关内容,下面我们来看具体详情!
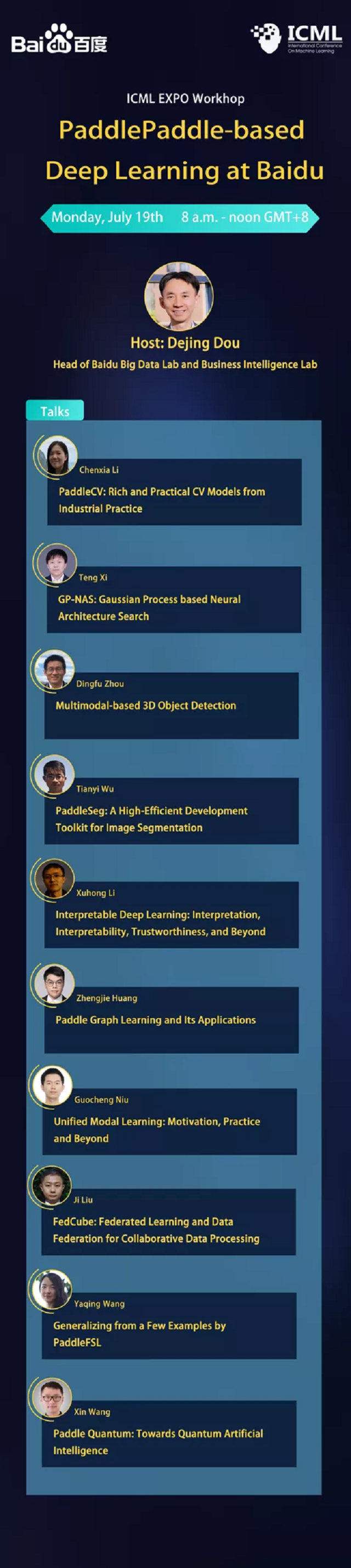
北京时间7月19日,由百度主办的ICML 2021 Expo正式召开,这也是本次由国内企业申请主办的唯一一个Expo。
在本次Expo上,来自百度的科研人员将介绍百度基于飞桨在计算机视觉、自然语言处理、语音、量子计算等多个技术领域的最新进展和产业实践积累,包含十个主题演讲。
百度飞桨亮相ICML展现多面AI技术实力
ICML(机器学习国际会议)作为国际机器学习学会(IMLS)主办的年度机器学习国际顶级会议,是国际机器学习领域探讨前沿科技成果和技术实践应用的重要舞台。
此次百度举办的Expo将从多个角度、全面展示飞桨在深度学习领域强大的技术优势和深厚的产业实践积累。
飞桨(PaddlePaddle)作为我国首个自主研发、功能丰富、开源开放的产业级深度学习平台,目前已经凝聚了320万开发者、服务企事业单位12万家,涵盖工业、能源、金融、医疗、农业、城市管理等多个领域。
不久前,飞桨开源框架正式升级到2.1版本,对自动混合精度、动态图、高层API等进行了优化,在模型套件方面文心ERNIE全新开源发布四大预训练模型,部署和硬件生态方面也持续拓展。
十大主题演讲干货十足期待碰撞技术火花
技术的发展离不开研究者潜心钻研,更需要相互交流碰撞灵感火花。本次百度举办的ICML 2021 Expo包含十个主题演讲,期待与全球AI顶尖人才展开广泛交流与学习,分享和探讨百度飞桨最新技术成果与应用心得。
以下为主题演讲介绍:
PaddleCV:Rich and Practical CV Models from Industrial Practice
主题一:PaddleCV:工业实践中丰富实用的CV模型
为了满足企业低成本开发和快速集成的需求,飞桨重点建设了大规模的官方模型库,包含经过产业实践长期打磨的主流模型以及在国际竞赛中的夺冠模型。百度资深算法工程师将为大家带来飞桨视觉模型库PaddleCV的技术分享。
PaddleCV作为飞桨重点研发的视觉模型库,为开发者提供了面向图像分类(PaddleClas)、目标检测(PaddleDetection)、图像分割(PaddleSeg)、文本识别(PaddleOCR)、图像生成(PaddleGAN)等视觉场景的多种端到端开发套件和海量视觉方向模型,其中PaddleOCR和PaddleDetection开发套件更是被众多企业广泛使用。飞桨开发套件围绕企业实际研发流程量身打造,服务企业遍布能源、金融、工业、农业等众多领域。
GP-NAS:Gaussian Process based Neural Architecture Search
主题二:GP-NAS:基于高斯过程的模型结构自动搜索技术
通过对深度神经网络进行模型结构自动搜索,NAS(Neural Architecture Search)在各类计算机视觉的任务中都超越了人工设计模型结构的性能。GP-NAS旨在解决NAS中的三个重要问题:如何衡量模型结构与其性能之间的相关性?如何评估不同模型结构之间的相关性?如何用少量样本学习这些相关性?
为此,GP-NAS首先从贝叶斯视角来对这些相关性进行建模。通过引入一种基于高斯过程的NAS新方法,并通过定制化的核函数和均值函数对相关性进行建模。并且,均值函数和核函数都可以在线学习,以实现针对不同搜索空间中的复杂相关性的自适应建模。
此外,通过结合基于互信息的采样方法,可以通过最少的采样次数就能估计/学习出GP-NAS的均值函数和核函数。在学习得到均值函数和核函数之后,GP-NAS就可以预测出不同场景,不同平台下任意模型结构的性能,并且从理论上得到这些性能的置信度。
GP-NAS不仅在CIFAR10和ImageNet等分类任务上取得了SOTA的实验结果,在人脸识别任务上同样取得了非常好的结果。本次分享还会介绍搜索空间的设计以及超网络的一致性问题,并介绍GP-NAS多次在国际比赛中夺冠的经历。
Multimodal-based 3D Object Detection
主题三:基于多模态的三维目标检测
精准的估计周围物体的三维位置对于自动驾驶系统非常重要。为了确保自动驾驶系统的安全性,无人驾驶汽车通常利用多种传感器(如相机、Lidar等)来感知周围的环境,在此次演讲中,百度分别介绍了基于不同传感器的三维物体检测算法。
首先介绍了利用CAD模型和CAD模型free的两种不同的基于单帧图像的三维物体位置估计算法。相机成本低廉,可以提供详细的纹理与颜色信息,实验表明对于距离较近的物体检测效果明显。
相比基于相机的估计算法,基于Lidar的三维物体检测算法效果显著提升。对于如何提升稀有类别的检测效果,始终是一个开放的研究问题。随后介绍了一种简单有效的基于Rendering的三维物体增强策略,能有效地考虑不同前景物体之间、以及前景与背景物体之间的遮挡关系。在公开数据集上的测试效果表明此算法对于所有类别的检测效果都有提升,尤其对于稀有类别的检测结果提升尤为显著。
最后,介绍了一种简单有效的基于2D/3D场景分割的多模型融合框架,同时挖掘图像和点云的优势,能有效地提升三维物体的检测结果。此前,该算法的升级版在ICRA2021 nuScenes三维物体检测公开赛上获得冠军。目前PaddlePadlle框架支持通用三维点云理解,包含基于点云的三维物体检测、分割以及基于单帧图像的三维物体位置估计等,将来会开源更多的基于点云的三维深度模型。
PaddleSeg:A High-Efficient Development Toolkit for Image Segmentation
主题四:高效图像分割工具——PaddleSeg
语义分割是非常重要并极具挑战的视觉任务,在人机交互、增强现实和无人驾驶领域有着重要的应用价值。本次演讲将介绍一个基于飞桨的语义分割算法平台PaddleSeg,它提供了许多经典的语义分割算法(FCN、DeepLab、PSPNet等)的实现。同时,演讲也会介绍百度最近基于PaddleSeg研发的一些新的语义分割算法。
Interpretable Deep Learning:Interpretation,Interpretability,Trustworthiness,and Beyond
主题五:可解释的深度学习——解释性、可解释性、可信赖性和超越性
深度学习模型目前已经在许多领域——比如计算机视觉、自然语言处理、生物、医疗等达到甚至超过了人类的水平。然而,深度学习模型一直被当做黑盒使用,其决策过程和判断标准始终让人难以理解。
基于目前主流的可解释性算法,在本次演讲中将系统地介绍深度学习模型的可解释性,包括可解释性的重要性、可解释性算法的分类以及如何评测这些算法的可靠性。百度开源了基于飞桨的可解释性算法代码库InterpretDL,集成了十数种可解释性算法,其中也包含了百度关于可解释性的最新研究工作,并将对其中的两项工作进行详细的介绍。百度的开源库InterpretDL全面解耦了算法与模型,并提供详尽的教程,方便易用,同时满足学术界和工业界的需求。
Paddle Graph Learning and Its Applications
主题六:飞桨图神经网络框架PGL及其应用
在本次演讲中,百度将会介绍高效易用的大规模图神经网络框架飞桨PGL。图神经网络最大的特点是能够建模样本与样本的连接信息,但是编码样本之间的关系,在原生的深度学习框架中一般都比较复杂。飞桨PGL采用消息传递范式作为图神经网络的编程接口,使得图神经网络的编写变得十分便利;并且针对图神经网络场景做了大量的性能优化,包括提出并行消息聚合、多卡并行FullBatch训练等技术,大大提升了图神经网络的工业实用性。
本演讲将展示飞桨PGL在图神经网络的研究上面取得的进展,并且分享具体案例,介绍如何通过万亿规模图引擎以及参数服务器的整合,落地工业级图神经网络应用。
Unified Modal Learning:Motivation,Practice and Beyond
主题七:统一模式学习——动机、实践与超越
现有的预训练技术关注于分开解决单模态任务或者多模态任务,忽视了使用一个统一的预训练模型同时解决单模、多模问题带来的好处以及对应的挑战。反观人类则非常擅长从多源异构数据中联合学习,从而更好地理解物理世界的相关概念。
基于此,百度提出统一模态学习,目标是从大规模图像、文字、图文对等数据中联合学习,并具备同时解决单模态任务和多模态任务的能力。基于飞桨,百度提出了一个统一模态学习框架UNIMO,并在多个自然语言处理和视觉-语言多模态任务上取得了领先成绩。百度希望统一模态学习,能够提供一条通向通用人工智能的可能思路,并且借助社区的力量共同建设。
FedCube:Federated Learning and Data Federation for Collaborative Data Processing
主题八:FedCube——用于协作数据处理的联邦学习和数据联合
近年来,数据和计算资源通常分布在用户终端、各个地区或组织的设备中。由于法律或法规的限制,分布式数据和计算资源不能在不同地区或组织之间直接聚合或共享,用于数据处理或机器学习任务。联邦学习和数据联邦在遵守法律法规、确保数据安全和数据隐私的前提下,有效利用分布式数据和计算资源,训练机器学习模型和协同处理数据。
在本次演讲中,百度展示包括PaddleFL在内的联邦学习系统的功能架构,并介绍了基于百度联邦学习系统的研究工作。
Generalizing from a Few Examples by PaddleFSL
主题九:基于飞桨的小样本学习工具库PaddleFSL
人工智能领域欣欣向荣,但现有技术通常需要大量标注数据和高算力的高性能计算设备支撑。与之对比,人类却可以利用已学习的知识,快速从几个示例中学到规则,这使得现在的人工智能距离“像人”还有较大距离。小样本学习(FSL)研究如何快速泛化到仅包含几个标注数据的新任务,是缩小人工智能和人类学习之间差距的重要一环。
此外,FSL使对罕见情况的学习成为可能,例如在药物发现中给定一些标记分子来预测新的分子特性。鉴于高质量的标记数据获取成本高,FSL的应用还有助于降低工业应用中收集大规模监督数据的收集、标注、处理和计算消耗。
在本次演讲中,百度将介绍基于飞桨的FSL工具包PaddleFSL。它包含了很多简单易用的FSL方法,支持图像分类、关系抽取等常见应用,同时易于扩展到新应用。百度希望PaddleFSL可以助力学术界和工业界的研究和开发者在各种场景下轻松探索FSL。
Paddle Quantum:Towards Quantum Artificial Intelligence
主题十:量桨——迈向量子人工智能
人工智能是新一轮产业变革的重要驱动,量子计算则是备受瞩目的前沿技术,二者的融合孕育出新的方向:量子人工智能,该演讲则带来了百度在该方向的最新进展。基于深度学习平台飞桨,百度研发了国内首个量子机器学习工具集“量桨”,旨在加速人工智能与量子计算的融合创新。
近期量桨发布2.1版本,运行效率平均提升20%,通过量子神经网络、量子核方法、含噪量子电路等模块,开发者们可以在量桨上便捷地进行人工智能、组合优化、量子化学方面的应用研发。借助深度学习对量子技术的赋能,量桨LOCCNet发现了新的纠缠提纯方案,相比业界现有方案取得了更好效果。此外,量桨官网qml.baidu.com提供了丰富教程与案例,助力开发者入门与研发。百度量子平台以量脉、量桨、量易伏为主体,旨在将用户和量子服务紧密结合,赋能教育、科学研究、工业生产等领域,构建开放、可持续的百度量子生态,最终实现“人人皆可量子”的美好愿景。