ERNIE-ViL类别文心·跨模态大模型应用视觉常识推理、视觉问答、跨模态检索、引用表达式理解等模型概述ERNIE-ViL 是业界首个融合场景图知识的多模态预训练模型。ERNIE-ViL将场景图知识融入到视觉-语言模型的预训练过程,学习场景语义的联合表示,显著增强了跨模态的语义理解能力。ERNIE-ViL 还在包括视觉常识推理、视觉问答、引用表达式理解、跨模态图像检索、跨模态文本检索等 5 项典型
免费申请测试 >> *价格优惠政策请联系客服咨询ERNIE-ViL 是业界首个融合场景图知识的多模态预训练模型。ERNIE-ViL 将场景图知识融入到视觉-语言模型的预训练过程,学习场景语义的联合表示,显著增强了跨模态的语义理解能力。
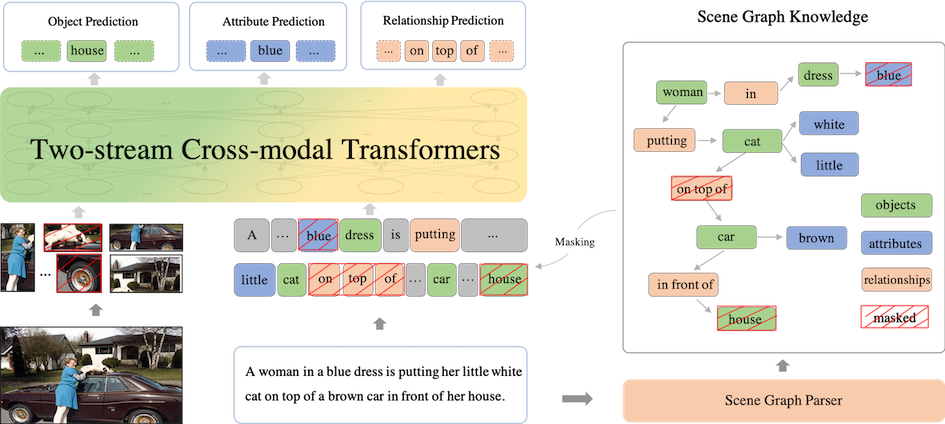
基于文本中解析出的场景图,ERNIE-ViL 提出了三个多模态场景图预测任务: 物体预测:随机选取图中的一部分物体,然后对其在句子中对应的词进行掩码和预测; 属性预测:对于场景图中的属性-物体组合,随机选取一部分词对其中属性词进行掩码和预测; 关系预测:对于场景图中的物体-关系-物体三元组,对其中的关系词进行掩码和预测。
ERNIE-ViL 在五个视觉语言下游任务进行了实验,包括视觉常识推理,视觉问答,跨模态图片检索,跨模态文本检索,引用表达式理解,与主流模型的效果对比可以参考开源论文。
ERNIE-ViL
类别文心·跨模态大模型
应用视觉常识推理、视觉问答、跨模态检索、引用表达式理解等
模型概述
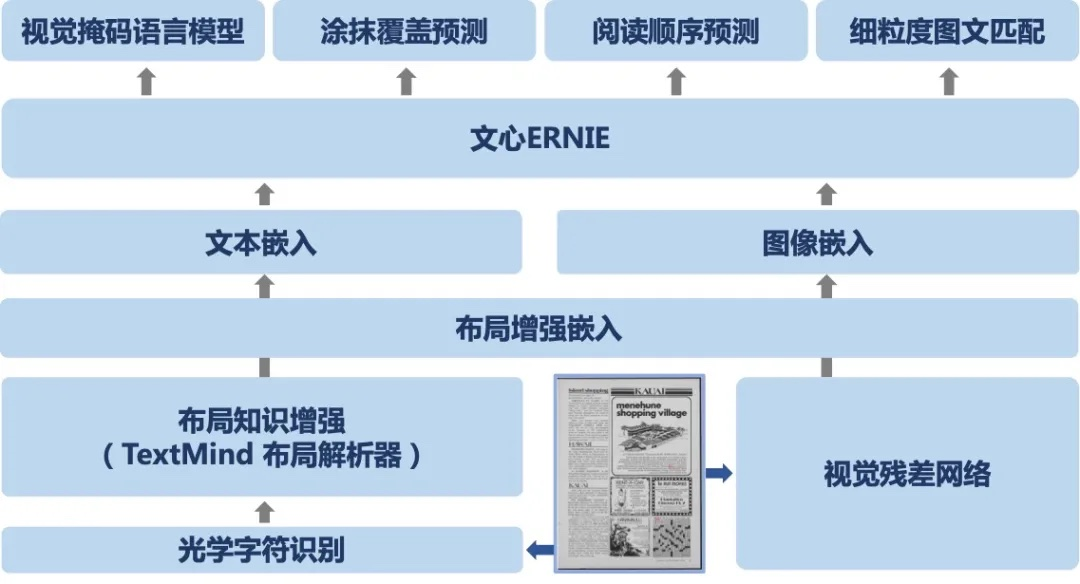
ERNIE-ViL 是业界首个融合场景图知识的多模态预训练模型。ERNIE-ViL将场景图知识融入到视觉-语言模型的预训练过程,学习场景语义的联合表示,显著增强了跨模态的语义理解能力。ERNIE-ViL 还在包括视觉常识推理、视觉问答、引用表达式理解、跨模态图像检索、跨模态文本检索等 5 项典型多模态任务中刷新了世界最好效果。并在多模态领域权威榜单视觉常识推理任务(VCR)上登顶榜首。
模型说明
ERNIE-ViL 是业界首个融合场景图知识的多模态预训练模型。ERNIE-ViL 将场景图知识融入到视觉-语言模型的预训练过程,学习场景语义的联合表示,显著增强了跨模态的语义理解能力。ERNIE-ViL 还在包括视觉常识推理、视觉问答、引用表达式理解、跨模态图像检索、跨模态文本检索等 5 项典型多模态任务中刷新了世界最好效果。并在多模态领域权威榜单视觉常识推理任务(VCR)上登顶榜首。
基于文本中解析出的场景图,ERNIE-ViL 提出了三个多模态场景图预测任务:
物体预测:随机选取图中的一部分物体,然后对其在句子中对应的词进行掩码和预测;
属性预测:对于场景图中的属性-物体组合,随机选取一部分词对其中属性词进行掩码和预测;
关系预测:对于场景图中的物体-关系-物体三元组,对其中的关系词进行掩码和预测。
ERNIE-ViL 场景图预训练任务结构
ERNIE-ViL 在五个视觉语言下游任务进行了实验,包括视觉常识推理,视觉问答,跨模态图片检索,跨模态文本检索,引用表达式理解,与主流模型的效果对比可以参考开源论文。
数据集合
训练、验证和测试集合相关数据可以由视觉常识推理官网获取;
视觉端特征的组织方式借鉴ViLBERT, 因此项目直接使用 ViLBERT 中的数据,数据下载地址;
将所有获取的文件放在 data/vcr 目录下;
任务预训练: 基于 ERNIE-ViL 的 out-of-domain 模型,在视觉推理任务中进行了任务预训练,预训练获得模型如下
ERNIE-ViL-VCR-task-pretrainbase
ERNIE-ViL-VCR-task-pretrainlarge
效果: ERNIE-ViL 在视觉常识推理任务上的效果对比如下:
| 模型 | Q->A | QA->R | Q->AR |
|---|---|---|---|
| ERNIE-ViL (task-pretrain) base | 76.37(77.0) | 79.65(80.3) | 61.24(62.1) |
| ERNIE-ViL (task-pretrain) large | 78.52(79.2) | 83.37(83.5) | 65.81(66.3) |
注:括号外表示验证集效果,括号内表示测试集效果,测试集效果提交到VCR 榜单获得。
数据集合
原始图片、问题和答案可以由视觉问答官网获取。
视觉端特征使用bottom-up attention中的工具提取,提取的 box 动态值为 100-100。
训练 & 测试数据按照如下方式组织:
question_id, question, answer_label, answer_score, image_w, image_h, number_box, image_loc, image_embeddings多个答案的label和score用 ‘|’ 分隔,和image相关的项均可以从bottom up attention的工具提取。
效果:ERNIE-ViL 的三种预训练模型在视觉问答任务下的效果如下表
| 模型 | test-dev | test-std |
|---|---|---|
| ERNIE-ViL base | 73.18 | 73.36 |
| ERNIE-ViL large | 73.78 | 73.96 |
| ERNIE-ViL-Out&in-domain large | 74.95 | 75.10 |
数据集合
原始图片和文本描述相关的数据,可以从这里获取。
视觉端特征使用bottom-up attention提取,提取的 box 动态值为 0-36。
文本相关的数据可以参见 data/flickr 给出的示例 flickr.dev.data,图片端特征组织方式为
image_w, image_h, number_box, image_loc, image_embeddings
效果
ERNIE-ViL 的三种预训练模型在**跨模态图片检索(Flickr30k 数据集)**上的效果如下表:
| 模型 | R@1 | R@5 | R@10 |
| ERNIE-ViL base | 74.44 | 92.72 | 95.94 |
| ERNIE-ViL large | 75.10 | 93.42 | 96.26 |
| ERNIE-ViL-Out&in-domain large | 76.66 | 94.16 | 96.76 |
ERNIE-ViL 的三种预训练模型在**跨模态文本检索(Flickr30k 数据集)**任务上的效果如下表:
| 模型 | R@1 | R@5 | R@10 |
|---|---|---|---|
| ERNIE-ViL base | 86.70 | 97.80 | 99.00 |
| ERNIE-ViL large | 88.70 | 97.30 | 99.10 |
| ERNIE-ViL-Out&in-domain large | 89.20 | 98.50 | 99.20 |
数据集合
视觉端特征参考了MAttNet的提取方式。
单条训练 & 验证 数据的组织方式为
expressions, image_w, image_h, number_box, number_boxes_gt, image_loc, image_embeddings, box_label, label
效果
ERNIE-ViL 的三种预训练模型在引用表达式理解任务上的效果如下表:
| 模型 | val | testA | testB |
|---|---|---|---|
| ERNIE-ViL base | 74.02 | 80.33 | 64.74 |
| ERNIE-ViL large | 74.24 | 80.97 | 64.70 |
| ERNIE-ViL-Out&in-domain large | 75.89 | 82.39 | 66.91 |
ERNIE-ViL 代码基于 Paddle Fluid 1.8 和 Python 2.7, 依赖的其他模块也列举在 requirements.txt,可以通过下面的指令安装:
pip install -r requirements.txt
在运行 ERNIE-ViL 微调前,需要将 CUDA 、cuDNN 、NCCL2 的动态库路径添加到 LD_LIBRARY_PATH 。 我们把下游任务的参数配置文件放到了 conf/ ,可以简单地通过配置文件运行。 例如,您可以通过下面的指令在各个下游任务上进行微调:
sh run_finetuning.sh $task_name(vqa/flickr/refcoco_plus/vcr) conf/${task_name}/model_conf_${task_name} $vocab_file $ernie_vil_config $pretrain_models_params前面提供的模型链接中包含了所有需要的文件, 包含词表文件,配置文件和预训练参数。微调相关的模型配置和参数配置可以通过 conf/ 目录下的文件找到,这里对论文最优结果(large 模型)的一些关键参数进行汇总:
| Tasks | Batch Size | Learning Rate | # of Epochs | GPUs | Layer Decay rate | Hidden dropout |
|---|---|---|---|---|---|---|
| Tasks | Batch Size | Learning Rate | # of Epochs | GPUs | Layer Decay rate | Hidden dropout |
| VCR | 16(x4) | 1e-4 | 6 | 4x V100 | 0.9 | 0.1 |
| VQA 2.0 | 64(x4) | 1e-4 | 15 | 4x V100 | 0.9 | 0.1 |
| RefCOCO+ | 64(x2) | 1e-4 | 30 | 2x V100 | 0.9 | 0.2 |
| Flickr | 8(x8) | 2e-5 | 40 | 8x V100 | 0.0 | 0.1 |
所有的下游任务的微调实验是在 32 GB 的英伟达 V100 GPU 上运行,如果您的 GPU 显存不够,可以考虑更多张卡运行或者减小配置中的 batch_size。
基于已经训练的模型,您可以通过下面的命令测试下游任务的效果(相关的配置文件可以从之前下载的包获得)
Task Q->A: sh run_inference.sh vcr qa $split(val/test) conf/vcr/model_conf_vcr $vocab_file $ernie_vil_config $model_params $res_file
Task Q->AR: sh run_inference.sh vcr qar $split(val/test) conf/vcr/model_conf_vcr $vocab_file $ernie_vil_config $model_params $res_file
VCR 的测试可以在一张 32GB 的英伟达 V100 GPU 上运行,测试的结果包含 Q->A 任务、QA->R 任务和 Q->AR 任务,其中 Q->AR 任务由前两个任务结果合并所得.
sh run_inference.sh vqa eval $split(val/test_dev/test_std) conf/vqa/model_conf_vqa $vocab_file $ernie_vil_config $model_params $res_file
注:VQA 的测试样本没有 label 信息,需要将结果文件提交到VQA 网站查看结果。
sh run_inference.sh refcoco_plus eval $split(val/test_A/test_B) conf/refcoco_plus/model_conf_refcoco_plus $vocab_file $ernie_vil_config $model_params $res_file
sh run_inference.sh flickr eval $split(dev/test) conf/flickr/model_conf_flickr $vocab_file $ernie_vil_config $model_params $res_file
注:Flickr 的结果是一个预测结果文件,可以参考 tools/get_recall.py 统计一下最终结果。
EasyDL 平台支持零代码定制图文匹配模型。训练模型的基本流程如下图所示,全程可视化简易操作,在数据已经准备好的情况下,最快 15 分钟即可获得定制模型。
联系方式
400-996-8756
微信公众号
手机站
COPYRIGHT 2007-2020 TUIDC ALL RIGHTS RESERVED 腾佑科技-百度AI人工智能_百度人脸识别_图像识别_语音识别提供商
地址:河南省郑州市姚砦路133号金成时代广场6号楼13层 I CP备案号:豫B2-20110005-1 公安备案号: 41010502003271
声明:本站发布的内容版权归郑州腾佑科技有限公司所有,本站部分素材来源于网络及网友投稿,若无意中侵犯了您的版权,请致电在线客服我们将在核实后予以删除!