今天给大家带来的是百度大脑自研自研EasyEdge,在超多AI芯片部署上相关表现,下面我们来看具体详情!
深度学习经过多年发展,AI已经深入人心,事实上,在图像、文本领域,AI在多个产业已经落地了诸多应用,我们熟知的自动驾驶、语音助手,背后就大量运用了AI技术。
当下,PaddlePaddle、TensorFlow、PyTorch这样的开源框架已经非常强大,为部署侧也提供了相关的开源组件,以求降低开发难度。以PaddlePaddle框架为例,为了支持端侧预测,提供了PaddleLite推理引擎;为了提升预测性能,提供了PaddleSlim模型压缩工具。但即便如此,一方面,使用这些工具仍然有一定的开发门槛,另一方面由于端侧硬件、系统种类繁多,各种加速芯片层出不穷,框架工具很难完全支持和适配。因此,端侧部署开发工作仍存在实实在在的挑战,成为开发者将AI模型真正用起来的“拦路虎”。面对这些问题,是否存在一个平台,能够缩短部署开发的时间,实现一键式部署?同时对模型进行压缩提速,实现高性能推理?
百度EasyEdge专为解决以上问题而生,EasyEdge以PaddleLite、PaddleSlim为基础,提供了简单易用的端上部署套件,实现不写代码直接部署模型到端侧,并支持二次开发。另外,EasyEdge也扩展了对主流端计算硬件的支持,适配更广泛的硬件平台、操作系统、模型类型,并针对特定加速芯片使用专有的计算库,实现进一步的性能提升。
AI模型端部署难点在哪里?
1、我的使用场景需要我将模型部署到端上,但是端上开发可能会面向嵌入式设备,操作系统也可能是Android、iOS,有一定的上手成本,怎样才能更轻松地把模型落地到硬件设备上?
2、这些年出了好多加速芯片、加速卡、边缘计算盒,价格便宜还不占地,我想知道它们跑模型能达到什么样的精度和性能,帮助我进行选型。
3、我训好的模型适配XX芯片,要在各种模型格式之间转来转去,有点头大,好不容易模型格式对齐了,又有算子OP不支持,我该怎么办才能让它跑起来?
4、我想换个芯片,却发现怎么各家芯片的端上推理模型格式都不一样,又得从头适配,模型转起来想想就头大。
5、费了九牛二虎之力,模型在端上跑起来了,可是速度不是太理想,我想让它跑得更快,更省内存。听说量化、剪枝、蒸馏这方面挺有用,但是好像自己研究代码耗时太久。
EasyEdge提供最广泛的硬件平台适配
上述问题是开发者在端上部署模型时经常遇到的难点,为了解决这些问题,百度推出了EasyEdge端与边缘AI服务平台。通过EasyEdge,开发者可以便捷地将AI模型部署到各式各样的AI芯片和硬件平台上。事实上,最近EasyEdge又新增支持了两个新的芯片系列:Atlas300+鲲鹏服务器以及瑞芯微多款NPU芯片(当前已适配RK3399Pro、RV1109、RV1126),下图是EasyEdge的适配芯片矩阵,目前,EasyEdge支持20+AI芯片与硬件平台,4大主流操作系统。
你想把模型部署到Windows PC上?没问题,安排!
发布到手机上?Android还是iOS,随便选!当然,Linux系统更加是支持的。
具体到推理芯片上面,EasyEdge支持了很多市面上常见的硬件,除了常见的CPU、GPU以及前面提到的新支持的芯片,我们还支持英伟达Jetson系列、比特大陆、海思NNIE系列、Intel VPU、主流手机上的NPU、GPU等芯片,以及百度自研的EdgeBoard系列边缘AI计算盒。嵌入式设备、ARM CPU,那都不是事,而且,在未来,EasyEdge还会不断适配更多的AI芯片、加速卡、边缘计算盒,持续为开发者降低端侧模型适配迁移的难度。
EasyEdge提供超全的模型适配
EasyEdge是专业的模型部署平台,已经预置在EasyDL中。EasyDL作为零门槛的AI开发平台,涵盖了完整的数据处理、模型训练与优化、服务部署等功能,支持了非常完整的模型类型,包含图像、文本、视频、语音、OCR等多种场景多种类型的模型。通过EasyDL训练的模型可以天然使用EasyEdge来方便的进行端上部署。
但如果你是专业的AI模型开发者,手上已经有训练好的深度学习模型,只是苦于模型部署的麻烦,也可以来EasyEdge发布您的端上部署包。对于这样的第三方模型,当前EasyEdge已经支持了PaddlePaddle、TensorFlow、PyTorch、Caffe、MXNet等诸多框架以及ONNX模型格式,支持的算法类型也包括了图像分类、物体检测、人脸识别等业界主流的各类算法。
EasyEdge提供更强的端上推理性能
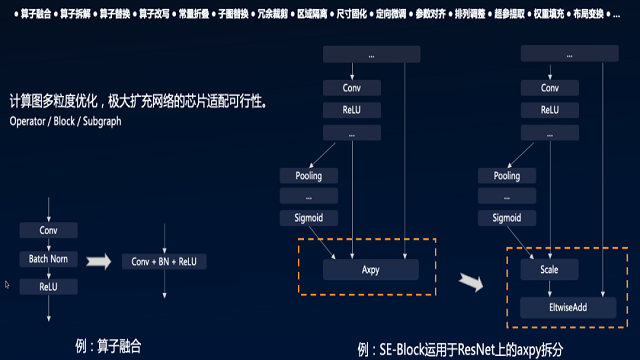
为了适配诸多AI芯片,EasyEdge针对不同芯片做了大量适配加速工作。因为在训练阶段,更多地关注模型效果及调优的灵活性。当训练完成后,模型就固化下来了。然而在端上部署时,关注点会变为模型的推理,在推理环节中的重点是推理性能。因此各家AI芯片厂商为了实现更高性能的推理能力,都在努力提高芯片的并行处理能力,或者通过GPU这样的超多线程并行处理,或者通过ASIC芯片这样极大增强芯片的单指令向量乃至矩阵处理能力。但不管怎样,线程化或者向量化带来算力巨大提升的同时,必然导致灵活性的下降。这也是为什么端侧AI芯片大都具有自己的模型格式和计算库。但同时也就带来了部署上面大量的适配和模型转换工作。
为此,EasyEdge内置了强大的模型互转工具,实现各个框架模型到统一IR的转换,再将统一的IR适配到各个端上。当模型部署到端上时,遇到有些OP不支持的情况时,EasyEdge提供了大量的OP优化和替换操作。同时,EasyEdge还会利用芯片的自定义OP功能或者底层的编程语言进行自定义OP的编写,以保证模型端到端地运行到AI芯片上。
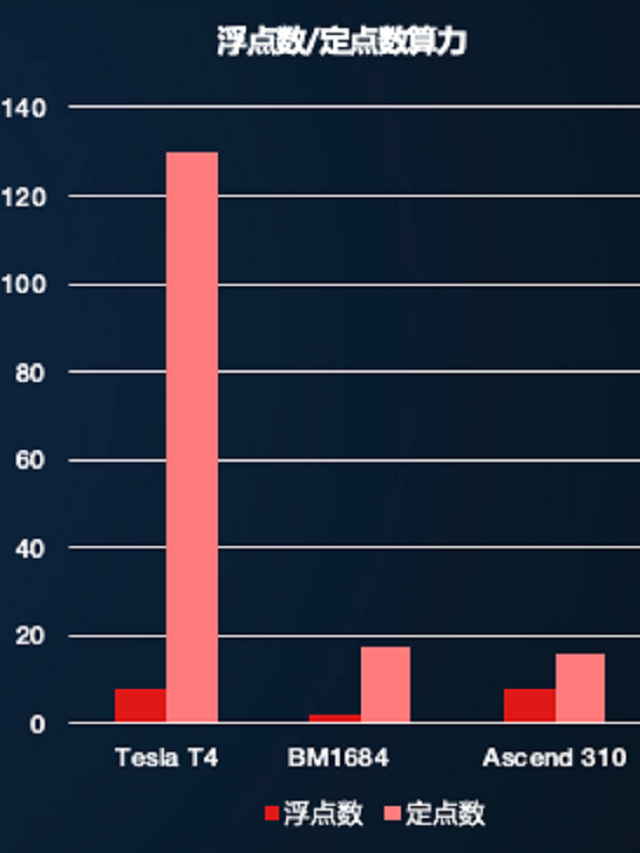
为了让模型跑的更快更省内存,模型压缩就是推理侧非常强大且实用的技术了。这方面,EasyEdge不仅支持了业界领先的量化、剪枝和蒸馏技术,还能够混合使用这几项能力,在尽可能保证效果的同时达到更好的压缩效果。左下图展示了几款常见硬件的定点数算力和浮点数算力的比对,可以看到在很多硬件上定点数算力都远大于浮点数算力,对于这样的硬件,量化是非常必要的。而右图中则可以看到剪枝和蒸馏对于模型推理的加速效果,剪枝和蒸馏本质都是对基础模型在尽量不影响精度的前提下进行精简,自然模型小了,内存占用就少了,推理时间也就短了。
EasyEdge内置全自动评估系统
EasyEdge内置全自动评估系统能展示模型精度、性能、内存等多维度评价指标,事实上,在EasyEdge,当你发布模型的时候,你通常能见到这样的网页:
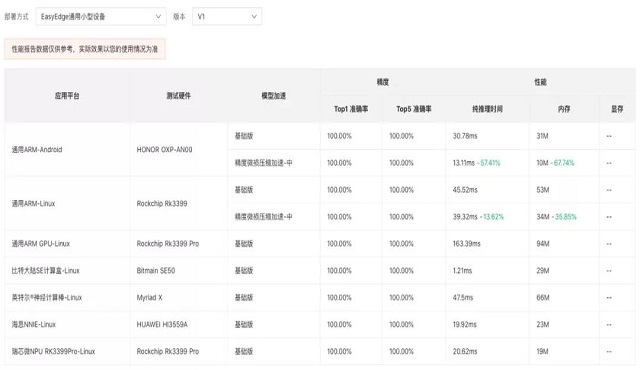
一次训练,多端部署。一个模型可以发布这么多的部署包,省去了一个个适配的麻烦。在这个页面上,我们还最新上线了模型效果评估的功能,打开性能评估报告,便能看到下面这样的页面。模型的精度、在对应硬件上的推理时间都一目了然的展示出来了(tips:这里的推理时间可不是经验时间,是你的模型真实在硬件跑出来的时间哦),有个这个报告,大家在部署前就能对自己的模型精度和性能情况了然于胸,是不是很贴心呢?
如果你选择SDK的方式进行模型部署,你将获取一个功能强大的部署包:不仅有完整且简单的接口,也有非常完善的demo工程,包括图片的推理、视频流的推理、多线程的推理等等,如果你是一个编程高手,相信你看完接口和demo,很快就能集成AI的能力去进行应用开发。那如果不想写代码就想部署模型怎么办呢?安排!
SDK里面提供了部署Serving服务的能力,不用写代码,运行一下编译出来的二进制,你的模型Serving服务就起来了,还附带H5页面,可以在这个页面上拖入图片看看效果。也可能通过http方式去请求Serving服务,操作非常便捷。事实上,EasyEdge的工具包中还有诸多类似这样方便开发和调试的小工具,限于篇幅没法一一列举,静待开发者来探索与体验。
快来训练部署你的模型吧!
相信通过前面的介绍,大家对于EasyEdge的多操作系统、多芯片适配的能力已经有了大体的认知了,那不妨亲自来体验一下。
EasyDL基于飞桨开源深度学习平台,面向企业AI应用开发者提供零门槛AI开发平台,实现零算法基础定制高精度AI模型。EasyDL提供一站式的智能标注、模型训练、服务部署等全流程功能,内置丰富的预训练模型,支持公有云、设备端、私有服务器、软硬一体方案等灵活的部署方式。准备好你的场景数据,去训练一个模型并部署到任何你们想部署的硬件上,使用EasyDL高效完成不是梦!
如果你已经有自己的模型,也可以去EasyEdge发布适配自己芯片的SDK和开发者套件哦。开发者套件使用十分简单便捷,无需关注深度学习、具体硬件等底层逻辑,只需关注输入图片和输出的识别结果即可。